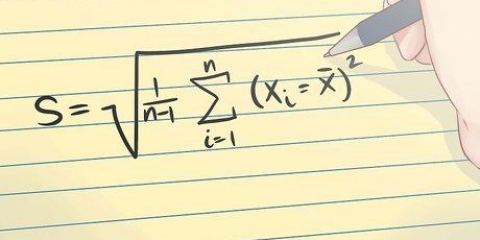För att beräkna urvalets medelvärde för data, lägg till alla vikter av de 1000 män du valt och dividera resultatet med 1000, antalet män. Genomsnittet i detta exempel är 180 pund. För att beräkna standardavvikelsen måste du beräkna medelvärdet av data. Nu är det nödvändigt att beräkna variansen av data, även känd som medelvärdet av kvadraten av skillnaderna från medelvärdet. När du har hittat detta tal, subtrahera dess kvadratrot. Anta att standardavvikelsen är 30 pund. (Ibland ges detta med en uppgift.) 

Bestäm det kritiska värdet, Za/2: Konfidensnivån är 95%. Konvertera denna procentsats till en decimal, 0,95, och dividera med 2 för att få 0,475. Titta sedan i nästa z tabell för att hitta värdet som motsvarar 0,475. Det närmaste värdet är 1,96, i skärningspunkten mellan rad 1,9 och kolumn 0,06. För att hitta standardfelet, ta standardavvikelsen 30 och dividera den med kvadratroten av urvalsstorleken (1000). Du får nu 30/31,6 = 0,95 pund. Multiplicera 1,96 med 0,95 (det kritiska värdet gånger standardfelet) och du får 1,86 eller felmarginalen. 
Du kan också använda följande praktiska formel för att hitta konfidensintervallet: x̅ ± Za/2 * σ/√(n). Här representerar x̅ medelvärdet.
Beräknar konfidensintervallet
Konfidensintervallet är en indikator på noggrannheten i dina avläsningar. Det indikerar också hur stabil din uppskattning är; i vilken grad dina avläsningar matchar din uppskattning om du skulle upprepa experimentet. Följ stegen nedan för att beräkna konfidensintervallet för din data.
Steg
1. Skriv ner det fenomen du vill testa. Anta att du arbetar med följande situation: Medelvikten för en manlig universitetsstudent A är 180 pund. Du ska nu testa hur exakt du kan förutsäga vikten av de manliga studenterna på universitet A med ett givet konfidensintervall.
2. Ta ett urval från din valda population. Detta är vad du kommer att använda för att samla in data för att testa din hypotes. Anta att du har valt 1000 slumpmässiga elever.
3. Beräkna provmedelvärde och standardavvikelse. Välj ett urval (d.v.s. urvalets medelvärde och standardavvikelse) som du vill använda för uppskattningen av den valda populationsparametern. En populationsparameter är en viss egenskap hos populationen. Här är provets medelvärde och standardavvikelse:
4. Välj den konfidensnivå du vill ha. De vanligaste konfidensnivåerna är 90 procent, 95 procent och 99 procent. Det är också möjligt att detta ges med en uppgift. Anta att du har valt 95 %.
5. Beräkna felmarginalen. Du kan hitta felmarginalen med följande formel: za/2 * σ/√(n).za/2 = konfidenskoefficient, där a = konfidensnivå, σ = standardavvikelse och n = urvalsstorlek. Detta är ett annat sätt att indikera att du måste multiplicera det kritiska värdet med standardfelet.Du löser formeln enligt följande, genom att dividera den:
6. Ange nu vad konfidensintervallet är. För att göra detta, ta medelvärdet (180) och notera det bredvid ± och felmarginalen. Svaret är: 180 ± 1,86. Du kan hitta de övre och nedre gränserna för konfidensintervallet genom att addera och subtrahera felmarginalen från medelvärdet. Så den nedre gränsen är 180 – 1,86 eller 178,14, och den övre gränsen är 180 + 1,86 eller 181,86.
Tips
- Både t-poäng och z-poäng kan beräknas manuellt, med en miniräknare eller med statistiska tabeller. Z-poäng kan också bestämmas med normalfördelningskalkylatorn och t-poäng med t-fördelningskalkylatorn. Onlineverktyg finns också tillgängliga.
- Urvalspopulationen måste vara normal för ett korrekt konfidensintervall.
- Det kritiska värdet som används för att beräkna felmarginalen är en konstant uttryckt som en t-poäng eller som en z-poäng. T-poäng är vanligtvis att föredra framför populationens standardavvikelse är okänd eller när ett litet urval används.
- Det finns många metoder, som slumpmässigt urval, systematiskt urval och stratifierat urval, som gör att du kan ta ett representativt urval att använda för hypotesprövning.
- Ett konfidensintervall säger ingenting om sannolikheten för ett visst utfall. Om du till exempel är 95 % säker på att ditt befolkningsmedelvärde ligger mellan 75 och 100 betyder konfidensintervallet på 95 % inte att det finns en 95 % chans att medelvärdet faller inom det beräknade intervallet.
Förnödenheter
- Testa data från en population
- Dator
- Internet anslutning
- En lärobok i statistik
- Grafisk miniräknare



Оцените, пожалуйста статью